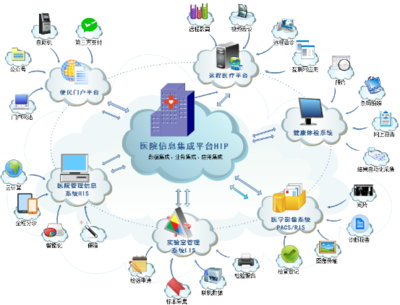
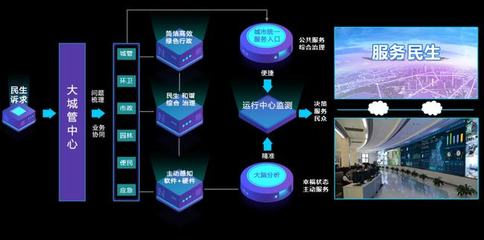
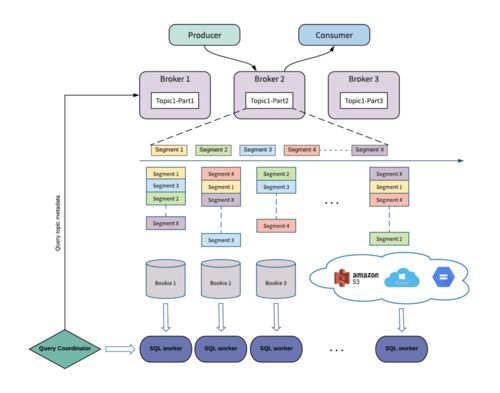
欢迎来到知识图谱专栏!本专栏致力于系统性地介绍知识图谱从基础构建到高级应用的完整技术链条,涵盖数据增强、智能标注、信息抽取、知识融合、知识推理及模型优化等核心领域,旨在为研究人员、工程师及技术爱好者提供一个深入探讨与学习的平台。
一、数据增强与智能标注:高质量知识的基石
构建可靠知识图谱的起点在于高质量的数据。数据增强技术通过引入噪声、同义替换、回译或生成对抗网络(GAN)等方法,在有限标注数据上扩充训练集,提升模型的泛化能力与鲁棒性。而智能标注则利用主动学习、半监督学习等技术,减少人工标注成本,通过模型与人工的交互迭代,高效产生精准的标注数据,为后续信息抽取任务奠定坚实基础。
二、文本信息抽取:从非结构化文本中提炼知识
信息抽取是将非结构化文本转化为结构化知识的核心步骤,主要包括:
- 实体抽取:识别文本中的命名实体,如人名、地点、机构名等。
- 关系抽取:确定实体之间的语义关系,如“创始人”、“位于”等。
- 事件抽取:检测文本中描述的事件及其相关要素(时间、地点、参与者等)。
本专栏将深入探讨基于规则、统计学习及深度学习(如BERT、图神经网络)的抽取方法,并分享处理噪声、歧义与稀疏性的实战经验。
三、知识融合与算法方案:构建统一的知识网络
从多源获取的知识常存在异构、冗余与冲突问题。知识融合通过实体对齐、属性融合与冲突消解等算法,将不同来源的知识整合为一致、丰富的知识库。我们将介绍基于相似度计算、图匹配及表示学习(如TransE)的融合方案,探讨如何提升知识图谱的完整性与准确性。
四、知识推理:挖掘深层次关联与隐含知识
知识推理利用现有知识推断新事实或关系,是知识图谱实现智能应用的关键。专栏将覆盖基于规则的推理(如一阶逻辑)、基于表示学习的推理(如嵌入模型),以及结合路径与图结构的推理方法,展示如何通过推理补全缺失知识、发现潜在关联,赋能问答系统、推荐系统等应用。
五、模型优化与压缩技术:迈向高效实用的部署
知识图谱模型常面临计算资源消耗大、部署困难等挑战。我们将探讨模型优化技术(如超参数调优、多任务学习)以提升性能,并详细介绍模型压缩方法,包括知识蒸馏、剪枝、量化及轻量化网络设计,旨在降低模型复杂度与存储开销,实现知识图谱系统在边缘设备或实时场景中的高效运行。
六、信息系统集成服务:从技术到落地应用
知识图谱的价值最终体现在与业务系统的集成。本专栏将分享知识图谱与现有信息系统(如CRM、ERP)集成的架构设计、API开发与运维实践,探讨如何通过可视化交互、实时查询与决策支持,将知识图谱技术转化为驱动业务智能的核心引擎。
本专栏将沿“数据→知识→应用”的主线,结合前沿研究与工程实践,为您呈现知识图谱技术的全貌。无论您是入门新手还是资深专家,都能在这里找到有价值的见解与解决方案。敬请关注后续文章,共同探索知识图谱的无限可能!